التعلم المعزز Reinforcement learning هو مجموعة فرعية من فروع التعلم الآلي الذي يتضمن تدريب وكيل لاتخاذ القرارات في بيئة من أجل الحصول على مكافأة. بمعنى آخر ، يتعلم الوكيل اتخاذ الإجراءات التي تؤدي إلى أفضل نتيجة ممكنة في موقف معين.
مكونات التعلم المعزز
فيما يلي بعض المكونات الرئيسية للتعلم المعزز:
- البيئة Environment: البيئة هي المكان الذي يعمل فيه الوكيل. يتكون من مجموعة من الحالات و الأفعال و المكافآت. يتفاعل الوكيل مع البيئة من خلال مراقبة الوضع الحالي ، و اتخاذ إجراء ، و الحصول على مكافأة.
- الوكيل Agent: الوكيل هو صانع القرار الذي يتعلم اتخاذ الإجراءات في البيئة. الهدف من الوكيل هو تعظيم المكافأة التراكمية التي يتلقاها بمرور الوقت.
- الإجراء Action: الإجراء هو قرار يتخذه الوكيل ويؤثر على حالة البيئة. تعتمد مجموعة الإجراءات الممكنة على البيئة.
- الحالة State: الحالة هي تمثيل للوضع الحالي في البيئة. يمكن أن تتضمن الحالة معلومات حول الموقع الحالي للوكيل ، وحالة الوكلاء الآخرين في البيئة ، وأي معلومات أخرى ذات صلة.
- المكافأة Reward: المكافأة هي إشارة يتلقاها الوكيل بعد اتخاذ إجراء في البيئة. يمكن أن تكون المكافأة موجبة أو سالبة أو صفرية وتعتمد قيمتها على البيئة.
- السياسة Policy: السياسة هي دالة تربط الحالات بالإجراءات. هدف الوكيل هو معرفة أفضل سياسة للبيئة ، والتي تزيد من المكافأة التراكمية المتوقعة.
كيف يعمل التعلم المعزز
في التعلم المعزز ، مثل ما تعرفنا في النص أعلاه ، يتعلم الوكيل كيفية التفاعل مع بيئة ما لتعظيم فكرة المكافأة التراكمية. هدف الوكيل هو معرفة السياسة التي تربط الحالات بالإجراءات ، من أجل تعظيم المكافأة التراكمية المتوقعة بمرور الوقت.
فيما يلي نظرة عامة مبسطة عن كيفية عمل التعلم المعزز:
- يتلقى الوكيل ملاحظة عن البيئة التي هو فيها ، والتي تتضمن عادةً معلومات حول الحالة الحالية للبيئة ، مثل مواضع الكائنات أو لوحة اللعبة الحالية.
- يستخدم الوكيل هذه الملاحظة لتحديد الإجراء الذي يجب اتخاذه ، بناءً على سياسته الحالية. السياسة هي تربط الحالات بالإجراءات ، ويتعلمها الوكيل بمرور الوقت.
- تستجيب البيئة للإجراء الذي يتخذه الوكيل ، مما ينتج عنه ملاحظة جديدة و إشارة مكافأة reward signal. إشارة المكافأة هي قيمة عددية تمثل الرغبة الفورية في ثنائي الإجراء و الحالة الحالية.
- يقوم الوكيل بتحديث سياسته بناءً على إشارة المراقبة والمكافأة التي تلقاها ، من أجل تحسين المكافأة التراكمية المتوقعة في المستقبل. تعتمد الخوارزمية المحددة المستخدمة لتحديث السياسة على خوارزمية التعلم المعزز المستخدمة.
- تتكرر الخطوات من 1 إلى 4 عدة مرات ، حيث يتفاعل الوكيل باستمرار مع البيئة ، ويتلقى التعليقات في شكل ملاحظات ومكافآت ، ويقوم بتحديث سياسته لتحسين أدائه. بمرور الوقت ، يتعلم الوكيل تحسين سياسته لتعظيم المكافأة التراكمية المتوقعة. يمكن أن يشمل ذلك المفاضلة بين المكافآت الفورية والمكافآت طويلة الأجل ، بالإضافة إلى موازنة استكشاف الإجراءات الجديدة واستغلال الإجراءات الجيدة المعروفة.
يمكن استخدام التعلم المعزز في مجموعة متنوعة من التطبيقات ، مثل الروبوتات و الألعاب و أنظمة التوصية. إنها أداة قوية لحل المشكلات حيث توجد مقايضة بين المكافآت قصيرة الأجل وطويلة الأجل ، وحيث يكون من الصعب أو المستحيل تحديد وظيفة موضوعية واضحة.
خوارزميات التعلم المعزز
هناك العديد من خوارزميات التعلم المعزز الشائعة التي يتم استخدامها بشكل متكرر في الممارسة. فيما يلي بعض منهم:
خوارزمية Q-Learning
هذه خوارزمية خالية من النماذج تتعلم تقدير وظيفة قيمة الإجراء المثلى عن طريق التحديث المتكرر لتقديراتها بناءً على المكافآت المرصودة.
خوارزمية SARSA
هذه خوارزمية أخرى خالية من النماذج تتعلم قيم Q لسياسة ما عن طريق تحديث تقديراتها بشكل متكرر بناءً على المكافآت المرصودة والحالة التالية والإجراء التالي الذي تم اتخاذه بموجب السياسة الحالية.
خوارزمية Deep Q-Network (DQN)
هذه الخوارزمية امتداد لخوارزمية Q-Learning التي تستخدم الشبكات العصبية العميقة لتمثيل وظيفة قيمة الإجراء. لقد ثبت أن DQN تحقق نتائج مبهرة في مجموعة متنوعة من البيئات ، بما في ذلك ألعاب مثل Atari و Go.
خوارزمية التدرج الإشتقاقي للسياسة Policy Gradient
هذه الفئة من الخوارزميات تتعلم السياسة مباشرة دون حساب دالة القيمة. يتم تمثيل السياسة عادةً من خلال شبكة عصبية يتم تدريبها لتعظيم المكافأة المتوقعة.
خوارزمية Actor-Critic
هذه خوارزمية هجينة تجمع بين مزايا كل من الأساليب القائمة على القيمة والطرق القائمة على السياسة. الممثل Actor مسؤول عن اختيار الإجراءات بناءً على السياسة ، بينما يقدر الناقد Critic دالة القيمة.
خوارزمية REINFORCE
هذه خوارزمية بسيطة للتدرج الإشتقاقي للسياسة تستخدم تقديرات مونت كارلو للتدرج لتحديث السياسة. إنها مفيدة بشكل خاص عندما تكون البيئة عشوائية وتكون المكافآت متفرقة.
خوارزمية تحسين النهج القريب Proximal Policy Optimization (PPO)
هذه خوارزمية متدرجة للسياسة متطورة تستخدم نهج منطقة الثقة للحد من حجم تحديثات السياسة. لقد ثبت أن خوارزمية PPO تحقق نتائج ممتازة على مجموعة واسعة من البيئات.
هذه مجرد أمثلة قليلة لخوارزميات التعلم المعزز المتوفرة. يعتمد اختيار الخوارزمية الصحيحة على المشكلة المحددة التي تحاول حلها ، بالإضافة إلى خصائص البيئة والبيانات.
تطبيقات التعلم الالي المعزز
فيما يلي بعض الأمثلة على تطبيقات التعلم المعزز:
- الألعاب: تم استخدام التعلم المعزز لإنشاء وكلاء يمكنهم لعب ألعاب مثل ألعاب Go و Chess و Atari على مستوى فوق طاقة البشر.
- الروبوتات: يمكن استخدام التعلم المعزز لتدريب الروبوتات على أداء مهام معقدة ، مثل إمساك الأشياء والمشي والطيران.
- التمويل: يمكن استخدام التعلم المعزز لاتخاذ قرارات التداول في الأسواق المالية ، حيث يكون الهدف هو زيادة الأرباح إلى أقصى حد مع إدارة المخاطر.
- التسويق: يمكن استخدام التعلم المعزز لتحسين موضع الإعلان والاستهداف ، حيث يكون الهدف هو زيادة النقرات أو التحويلات.
- تخصيص الموارد: يمكن استخدام التعلم المعزز لتحسين تخصيص الموارد في الأنظمة المعقدة ، مثل إدارة حركة المرور أو إدارة شبكة الطاقة.
- أنظمة التوصيات: يمكن استخدام التعلم المعزز لإنشاء توصيات مخصصة للمنتجات أو الخدمات ، حيث يكون الهدف هو زيادة رضا العملاء أو مشاركتهم.
- الرعاية الصحية: يمكن استخدام التعلم المعزز لتطوير خطط علاج مخصصة للمرضى ، حيث يكون الهدف هو تعظيم النتائج الصحية للمريض.
- أنظمة التحكم الصناعي: يمكن استخدام التعلم المعزز لتحسين أنظمة التحكم في التصنيع والأماكن الصناعية الأخرى ، حيث يكون الهدف هو زيادة الكفاءة وتقليل التكاليف.
بشكل عام ، التعلم المعزز لديه القدرة على أن يكون أداة قوية لصنع القرار في البيئات الديناميكية المعقدة. ومع ذلك ، قد يكون من الصعب تطبيقه في الممارسة العملية ، لأنه يتطلب ضبطًا دقيقًا للمعلمات الفائقة ويمكن أن يكون مكلفًا من الناحية الحسابية. ومع ذلك ، مع استمرار تطور المجال ، يمكننا أن نتوقع رؤية المزيد من تطبيقات التعلم المعزز في مجموعة متنوعة من الإعدادات.
الإختلاف بين التعليم المعزز و تعلم الالة الأخرى
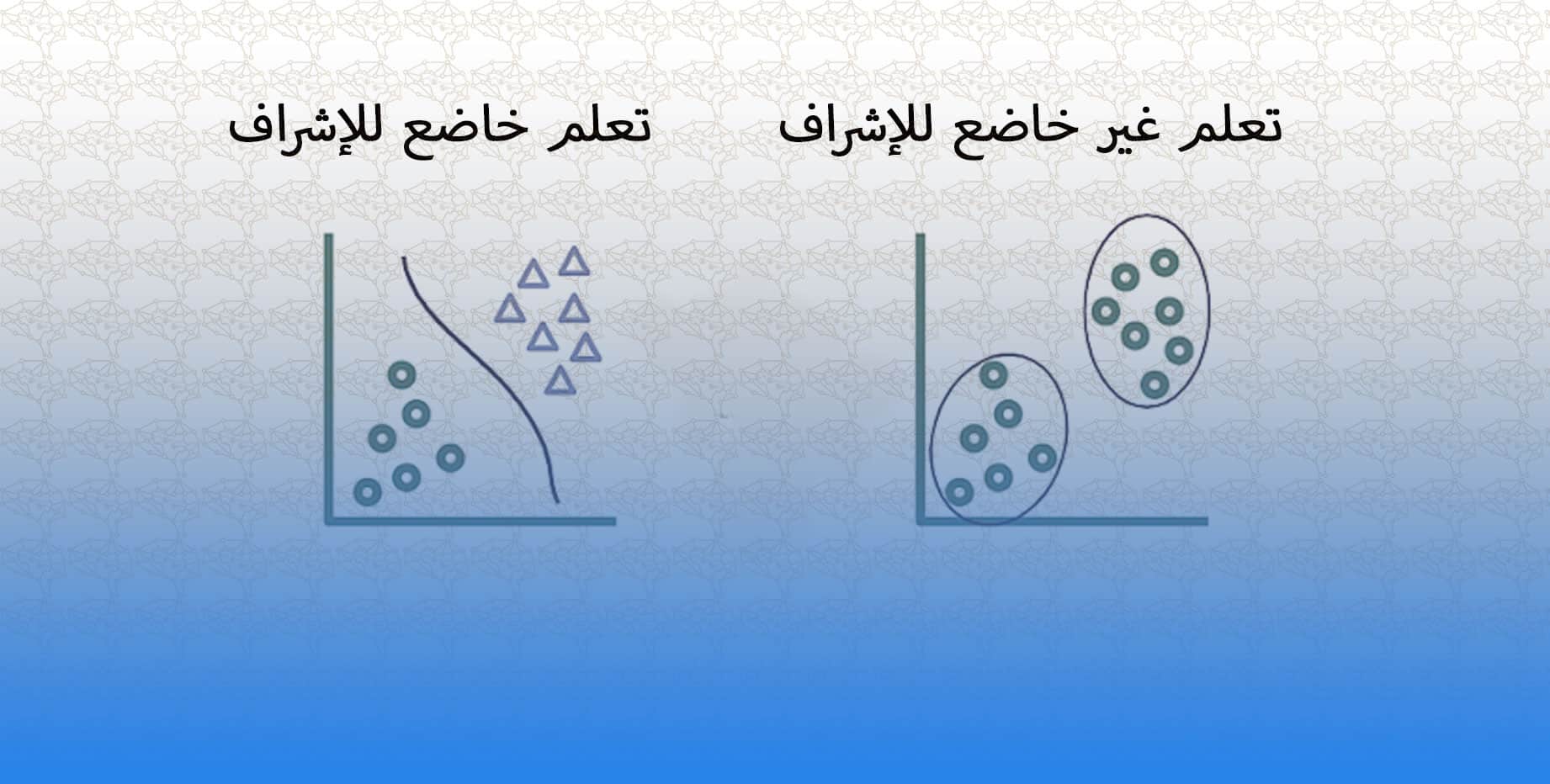
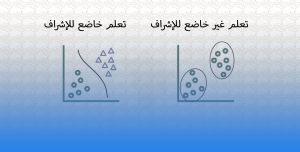
التعلم المعزز هو نوع من التعلم الآلي يختلف عن الأنواع الأخرى من التعلم الآلي ، مثل التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف ، بعدة طرق رئيسية:
الإشراف Supervision:
في التعلم الخاضع للإشراف ، يتم تدريب النموذج على مجموعة بيانات مرمزة ، حيث يتم توفير المخرجات الصحيحة لكل إدخال. في التعلم المعزز ، لا توجد مجموعة بيانات معنونة ، ويتعلم النموذج من تفاعلات التجربة والخطأ مع البيئة.
التغذية الراجعة Feedback:
في التعلم الخاضع للإشراف ، يتم تقديم الملاحظات على شكل ميزات labels، بينما في التعلم المعزز ، يتم تقديم الملاحظات في شكل مكافآت أو عقوبات.
الهدف Goal:
في التعلم الخاضع للإشراف ، الهدف هو تعلم الدالة التي تربط المدخلات بالمخرجات. في التعلم المعزز ، الهدف هو تعلم السياسة التي تربط الحالات بالإجراءات من أجل تعظيم إشارة المكافأة.
الاستكشاف مقابل الاستغلال Exploration vs. exploitation:
في التعلم المعزز ، يجب على الوكيل أن يوازن بين استكشاف البيئة للتعرف على الحالات والإجراءات الجديدة ، مع استغلال معرفته الحالية لتعظيم المكافآت. في التعلم الخاضع للإشراف ، ليست هناك حاجة للاستكشاف.
تعيين ائتمان مؤقت Temporal credit assignment:
في التعلم المعزز ، يجب أن يتعلم الوكيل تعيين رصيد للإجراءات التي أدت إلى المكافأة ، حتى لو حدثت في خطوات سابقة في الماضي. في التعلم الخاضع للإشراف ، يتم التعامل مع كل زوج من المدخلات والمخرجات بشكل مستقل.
ردود الفعل غير المحدودة Unbounded feedback:
في التعلم المعزز ، يتلقى الوكيل الملاحظات بشكل مستمر بمرور الوقت ، بينما في التعلم الخاضع للإشراف ، يتم تقديم الملاحظات فقط أثناء التدريب. بشكل عام ، التعلم المعزز هو نوع من التعلم الآلي مناسب تمامًا للمشكلات التي لا تتوفر فيها مجموعة بيانات مرمزة ، ويجب أن يتعلم الوكيل من تفاعلات التجربة والخطأ مع البيئة.
يمكن استخدام التعلم المعزز لتعلم السياسات التي تعمل على تحسين إشارات المكافآت في البيئات المعقدة ، مثل الألعاب والروبوتات وأنظمة التحكم. ومع ذلك ، يمكن أن يكون تطبيق التعلم المعزز صعبًا في الممارسة العملية ، لأنه يتطلب ضبطًا دقيقًا للمعلمات الفائقة ويمكن أن يكون مكلفًا من الناحية الحسابية.