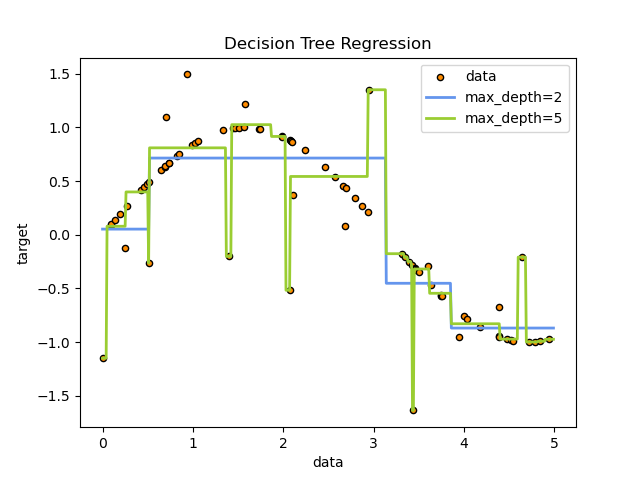
خوارزمية أشجار القرار (DTs) أو خوارزمية شجرة القرار هي خوارزمية من خوارزميات التعلم الالي الخاضع للإشراف تستخدم لحل مسائل التصنيف والتنبؤ الهدف هو إنشاء نموذج يتنبأ بقيمة المتغير المستهدف من خلال تعلم قواعد القرار البسيطة مستنتجة من ميزات البيانات. على سبيل المثال ، في المثال أدناه ، تتعلم الخوارزمية من البيانات لتقريب المنحنى الجيبي مع مجموعة من قواعد القرار if-then-else. كلما كانت الشجرة أعمق ، كلما كانت قواعد القرار أكثر تعقيدًا وأصبح النموذج أكثر تناسبا.
مزايا خوارزمية شجرة القرار
- سهلة الفهم والتفسير. أي يمكن تصور الشجرة.
- يتطلب القليل من الجهد لإعداد البيانات. غالبًا ما تتطلب التقنيات الأخرى ضبط البيانات، ويجب إنشاء متغيرات وهمية وإزالة القيم الفارغة. ملاحظة هذه الخوارزمية لا تدعم القيم المفقودة.
- تكلفة استخدام الشجرة (أي التنبؤ بالبيانات) هي لوغاريتمية في عدد نقاط البيانات المستخدمة لتدريب الشجرة.
- قادرة على التعامل مع كل من البيانات العددية والفئوية. عادة ما تكون التقنيات الأخرى متخصصة في تحليل مجموعات البيانات التي تحتوي على نوع واحد فقط من المتغيرات.
- قادرة على حل مسائل الإخراج المتعدد.
- من الممكن التحقق من أداء الخوارزمية باستخدام الاختبارات الإحصائية. هذا يجعل من الممكن حساب وثوقية النموذج.
- تعمل بشكل جيد حتى لو تم كسر افتراضاته إلى حد ما بواسطة النموذج الحقيقي الذي تم إنشاء البيانات منه.
عيوب خوارزمية شجرة القرار
- يمكن لمتعلمي شجرة القرار إنشاء أشجار معقدة للغاية لكن لا تعمل على تعميم البيانات بشكل جيد. وهذا ما يسمى بالافراط في التخصيص. آليات مثل التقليم pruning، وتحديد الحد الأدنى لعدد العينات المطلوبة في عقدة الورقة أو تحديد أقصى عمق للشجرة ، ضروري لتجنب هذه المشكلة.
- يمكن أن تكون شجرة القرار غير مستقرة لأن الاختلافات الصغيرة في البيانات قد تؤدي إلى إنشاء شجرة مختلفة تمامًا. يتم تخفيف هذه المشكلة باستخدام أشجار القرار داخل مجموعة.
- تعتمد خوارزميات التعلم العملية لشجرة القرار على خوارزميات الكشف عن مجريات الأمور heuristic algorithms مثل الخوارزمية الجشعة greedy algorithm ( هي خوارزمية التي تستند على الحدس المهني الذي يتم عن طريقه اختيار الإمكانية الأفضل المرئية في المرحلة الحالية، من دون الأخذ بالحسبان تأثير هذه الخطوة على تكملة الحل. الخوارزميات الجشعة مشهورة في حل مشاكل الاستمثال، حيث يتم عن طريقها محاولة الوصول إلى الجواب الأفضل ) حيث يتم اتخاذ القرارات المثلى مكانيا locally في كل عقدة.
- هناك مفاهيم يصعب تعلمها لأن أشجار القرار لا تعبر عنها بسهولة ، مثل مشاكل XOR.
- إذا هيمنت بعض الفئات قد يتم إنشاء أشجار منحازة. لذا يوصى بموازنة مجموعة البيانات قبل ملاءمتها لشجرة القرار.
مثال على التصنيف Classification
مصنف DecisionTreeClassifier في بايثون هو مصنف قادر على إجراء تصنيف متعدد الفئات في اي مجموعة بيانات. و كما هو الحال مع المصنفات الأخرى ، يأخذ مصنف DecisionTreeClassifier مصفوفين كمدخل : مصفوف X ، متناثر أو كثيف ، بحجم [n_samples ، n_features] يحتوي على عينات التدريب ، ومصفوف Y من القيم الصحيحة ، الحجم [n_samples] ، مع الاحتفاظ بتسميات الفئات لـ عينات التدريب:
>>> from sklearn import tree >>> X = [[0, 0], [1, 1]] >>> Y = [0, 1] >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, Y)
بعد تطبيقه و تجهيزه، يمكن استخدام النموذج للتنبؤ بفئة العينات:
>>> clf.predict([[2., 2.]]) array([1])
بدلاً من ذلك ، يمكن التنبؤ باحتمال كل فئة ، وهو جزء من عينات التدريب من نفس الفئة في الورقة:
>>> clf.predict_proba([[2., 2.]]) array([[0., 1.]])
مصنف DecisionTreeClassifier قادر على حل مسائل التصنيف ثنائي الفئات (حيث تكون التسميات [-1 ، 1]) والتصنيف متعدد الفئات (حيث التسميات هي [0 ،… ، K-1]).
باستخدام مجموعة بيانات زهرة السوسن Iris ، يمكننا إنشاء شجرة قرار على النحو التالي:
>>> from sklearn.datasets import load_iris >>> from sklearn import tree >>> X, y = load_iris(return_X_y=True) >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, y)
بمجرد تدريب النموذج، يمكنك رسم الشجرة باستخدام الامر plot_tree:
>> tree.plot_tree(clf.fit(iris.data, iris.target))
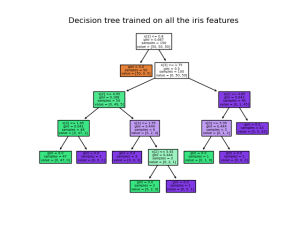
يمكننا أيضًا تصدير الشجرة الموضحة أعلاه بتنسيق Graphviz باستخدام الامر export_graphviz. إذا كنت تستخدم حزمة Conda
ويمكن تثبيتها في حزمة بايثون باستخدام الكود
conda install python-graphviz
او يمكن تثبيتها عن طريق الكود
pip install graphviz
فيما يلي مثال على تصدير ملف Graphviz للشجرة أعلاه المدربة على مجموعة بيانات زهرة السوسن بأكملها ؛ يتم حفظ النتائج في ملف إخراج iris.pdf:
>>> import graphviz
>>> dot_data = tree.export_graphviz(clf, out_file=None)
>>> graph = graphviz.Source(dot_data)
>>> graph.render("iris")
يدعم export_graphviz المصدِّر أيضًا مجموعة متنوعة من الخيارات الجمالية ، بما في ذلك عقد التلوين حسب فئتها (أو قيمة الانحدار) واستخدام أسماء متغيرات وفئات صريحة إذا رغبت في ذلك. كما تقدم Jupyter notebooks هذه الرسوم البيانية مضمنة تلقائيًا:
>> dot_data = tree.export_graphviz(clf, out_file=None,
... feature_names=iris.feature_names,
... class_names=iris.target_names,
... filled=True, rounded=True,
... special_characters=True)
>>> graph = graphviz.Source(dot_data)
>>> graph

وبالاضافة إلى ذلك ، يمكن أيضًا تصدير الشجرة بتنسيق نصي مع الكود export_text. لا تتطلب هذه الطريقة تثبيت مكتبات خارجية و تعتبر أكثرها إحكاما:
>> from sklearn.datasets import load_iris
>>> from sklearn.tree import DecisionTreeClassifier
>>> from sklearn.tree.export import export_text
>>> iris = load_iris()
>>> decision_tree = DecisionTreeClassifier(random_state=0, max_depth=2)
>>> decision_tree = decision_tree.fit(iris.data, iris.target)
>>> r = export_text(decision_tree, feature_names=iris['feature_names'])
>>> print(r)
|--- petal width (cm) <= 0.80
| |--- class: 0
|--- petal width (cm) > 0.80
| |--- petal width (cm) <= 1.75
| | |--- class: 1
| |--- petal width (cm) > 1.75
| | |--- class: 2
<BLANKLINE>