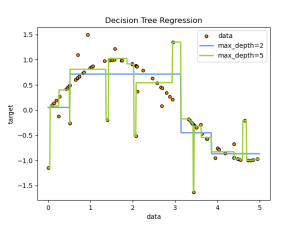
خوارزمية شجرة القرار هي خوارزمية من خوارزميات التعلم الالي الخاضع للإشراف التي يتم استتخدامها لحل مسائل التصنيف والتنبؤ. الهدف هو إنشاء نموذج يتنبأ بقيمة المتغير المستهدف من خلال تعلم قواعد القرار البسيطة مستنتجة من ميزات البيانات. على سبيل المثال ، في المثال أدناه ، تتعلم الخوارزمية من البيانات لتقريب المنحنى الجيبي مع مجموعة من قواعد القرار if-then-else. كلما كانت الشجرة أعمق ، كلما كانت قواعد القرار أكثر تعقيدًا وأصبح النموذج أكثر تناسبا.
يمكن تطبيق خوارزمية أشجار القرار على مشاكل التنبؤ ، باستخدام مصنف DecisionTreeRegressor ، كما هو الحال في إعدادات التصنيف التي ذكرناها في البوست السابق. ان طريقة الملاءمة المطبقة هنا هي إشاء مصفوفات وسيطة argument arrays (X و Y) ، إلا أنه في هذه الحالة من المتوقع أن تحتوي Y على قيم فاصلة عائمة بدلاً من قيم صحيحة.
مثال عملي لحل مسائل التنبؤ بإستخدام خوارزمية شجرة القرار بلغة البايثون
في هذا المثال سنستخدم الخوارزمية من اجل ايجاد أفضل تناسب لمنحنى دالة الجيب مع ملاحظة وجود قيم إضافية كقيم متطرفة. حيث تتعلم الخوارزمية الانحدارات الخطية المحلية التي تقارب منحنى دالة الجيب. يمكننا ملاحظة أنه إذا كانت قيمة أقصى عمق للشجرة (يتم التحكم فيه بواسطة المعامل max_depth) مرتفعة جدًا ، فإن شجرة القرار تتعلم تفاصيل دقيقة جدًا عن بيانات التدريب وتتعلم من القيم المتطرفة ، أي أنها تخصص بشكل مفرط. المثال موجود على scikit-learn:
# Import the necessary modules and libraries
importnumpyasnpfromsklearn.treeimportDecisionTreeRegressorimportmatplotlib.pyplotasplt
# Create a random dataset
rng=np.random.RandomState(1)X=np.sort(5*rng.rand(80,1),axis=0)y=np.sin(X).ravel()y[::5]+=3*(0.5-rng.rand(16))
# Fit regression model
regr_1=DecisionTreeRegressor(max_depth=2)regr_2=DecisionTreeRegressor(max_depth=5)regr_1.fit(X,y)regr_2.fit(X,y)
# Predict
X_test=np.arange(0.0,5.0,0.01)[:,np.newaxis]y_1=regr_1.predict(X_test)y_2=regr_2.predict(X_test)
# Plot the results
plt.figure()plt.scatter(X,y,s=20,edgecolor="black",c="darkorange",label="data")plt.plot(X_test,y_1,color="cornflowerblue",label="max_depth=2",linewidth=2)plt.plot(X_test,y_2,color="yellowgreen",label="max_depth=5",linewidth=2)plt.xlabel("data")plt.ylabel("target")plt.title("Decision Tree Regression")plt.legend()plt.show()
استخدام خوارزمية أشجار القرار لحل مسائل التنبؤ بلغة البايثون
اخيرا ، خوارزمية شجرة القرار قادرة على التعامل مع كل من البيانات العددية والفئوية. حيث عادة ما تكون التقنيات الأخرى متخصصة في تحليل مجموعات البيانات التي تحتوي على نوع واحد فقط من المتغيرات. لكن في المقابل ، ممكن أن تكون خوارزمية شجرة القرار غير مستقرة. و ذلك بسبب ان الاختلافات الصغيرة في البيانات قد تؤدي إلى إنشاء شجرة مختلفة تمامًا. لكن يتم تخفيف هذه المشكلة باستخدام أشجار القرار داخل مجموعة. في الاخير، يمكن قراءة البوستات المتعلقة بالخوارزمية على الموقع.
Share on facebook
فيسبوك
Share on twitter
تويتر
Share on linkedin
لينكدإن
Share on whatsapp
واتساب
علـــومــ 24
موقع متخصص في مجالي الطاقة المتجددة و الذكاء الاصطناعي