يوضح هذا المثال كيفية القيام بتصنيف الصور من الصفر في بايثون، بدءًا من ملفات صور JPEG على سطح المكتب، دون الاستفادة من الأوزان المدربة مسبقًا أو النماذج المصممة سابقا. نعرض سير العمل على مجموعة بيانات التصنيف الثنائي (لتصنيف صور الكلاب و القطط) اسم مجموعة البيانات على موقع كاقل Kaggle Cats vs Dogs.
نستخدم هنا الأداة image_dataset_from_directory لإنشاء مجموعات البيانات ، ونستخدم طبقات المعالجة المسبقة لصور Keras لضبط ابعاد الصور image standardization وزيادة البيانات data augmentation.
في البداية نقوم بتثبيات المكتبات اللازمة
تنسرفلو tensorflow هي مكتبة برمجية مجانية ومفتوحة المصدر في مجال تعلم الآلة. تستخدم في العديد من المجالات الفرعية ولكن لها تركيز محدد في تدريب واستدلال الشبكات العصبية العميقة. هي مكتبه رياضيات رمزية مبنية على برمجة تنقل المعطيات والبرمجة التفاضلية، كما انها تستخدم في تطبيقات تعلم الآلة مثل الشبكات العصبية.
كيراس keras هي مكتبة شبكات عصبية مفتوحة المصدر مكتوبة بلغة بايثون. يمكن أن تعمل بالاعتماد على تنسرفلو، أدوات ميكروسوفت الإدراكية، لغة آر، Theano، أو PlaidML. صُمّمت لتمكين إجراء التجارب على الشبكات العصبية العميقة بشكل سريع، و قد صممت على أن تكون سهلة الاستخدام ومرنة وقابلة للتوسيع.
ومن كيراس نقوم بإستيراد دالة الطبقات layers
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers
ثم نقوم بتحميل البيانات مجموعة بيانات القطط و الكلاب Kaggle Cats vs Dogs
أولاً ، نقم بتنزيل الملف نوع ZIP من البيانات الأولية بإستخدام الكود التالي:
!curl -O https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB -4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip
ثم نقوم بفك ضغط الملف
!unzip -q kagglecatsanddogs_3367a.zip !ls
الآن لدينا مجلد PetImages يحتوي على مجلدين فرعيين ، Cat و Dog. يحتوي كل مجلد فرعي على ملفات صور لكل فئة.
!ls PetImages
بعد ذلك نقوم بتصفية و تنقية البيانات من الصور التالفة
عند العمل مع الكثير من بيانات الصورة في العالم الحقيقي ، فإن و جود الصور التالفة أمر شائع. بمساعدة الكود أدناه بإستطاعتنا تصفية بيانات الصور من الصور التالفة و الصور التي لا تحتوي على السلسلة “JFIF” في رؤوسها.
import os
num_skipped = 0
for folder_name in ("Cat", "Dog"):
folder_path = os.path.join("PetImages", folder_name)
for fname in os.listdir(folder_path):
fpath = os.path.join(folder_path, fname)
try:
fobj = open(fpath, "rb")
is_jfif = tf.compat.as_bytes("JFIF") in fobj.peek(10)
finally:
fobj.close()
if not is_jfif:
num_skipped += 1
# Delete corrupted image
os.remove(fpath)
print("Deleted %d images" % num_skipped)
بمجرد ما ننتهي من إزالة الصور التالفة ننشئ مجموعة بيانات
image_size = (180, 180) batch_size = 32 train_ds = tf.keras.preprocessing.image_dataset_from_directory( "PetImages", validation_split=0.2, subset="training", seed=1337, image_size=image_size, batch_size=batch_size, ) val_ds = tf.keras.preprocessing.image_dataset_from_directory( "PetImages", validation_split=0.2, subset="validation", seed=1337, image_size=image_size, batch_size=batch_size, )
من أجل التحقق نقوم بعرض البيانات
إليك أول 9 صور في مجموعة بيانات التدريب. كما ترى ، التسمية 1 هي “كلب dog” والتسمية 0 هي “قط cat”.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(int(labels[i]))
plt.axis("off")

استخدام تقنية زيادة البيانات Data augmentation
عندما لا يكون لدينا مجموعة بيانات صور كبيرة بالقدر الكافي، فمن الممارسات الجيدة تقديم تنوع العينة بشكل مصطنع من خلال تطبيق تحويلات عشوائية لكنها واقعية على صور التدريب ، مثل التقليب الأفقي العشوائي أو التدوير العشوائي الصغير. يساعد هذا في تعريض النموذج لجوانب مختلفة من بيانات التدريب مع تقليل فرط التجهيز.
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
]
)
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")

ضبط و معالجة البيانات
float32 batches بواسطة مجموعة البيانات الخاصة بنا. ومع ذلك ، فإن قيم قناة RGB الخاصة بالصور تقع في النطاق [0 ، 255]. هذا ليس مثاليًا للشبكة العصبية ؛ بشكل عام ، يجب أن نسعى إلى جعل قيم المدخلات الخاصة بنا صغيرة. هنا ، سنقوم بتوحيد القيم لتكون على شكل [0 ، 1] باستخدام طبقة إعادة القياس Rescaling layer في بداية نموذجنا.هناك خياران للمعالجة المسبقة للبيانات. هناك طريقتان يمكنك من خلالهما استخدام المعالجة المسبقة data_augmentation:
- الخيار 1: جعله جزءًا من النموذج ، مثل هذا:
inputs = keras.Input(shape=input_shape)
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(x)
... # Rest of the modelباستخدام هذا الخيار ، ستتم زيادة بياناتك على الجهاز ، بشكل متزامن مع بقية تنفيذ النموذج ، مما يعني أنه سيستفيد من تسريع وحدة معالجة الرسومات.
لاحظ أن زيادة البيانات غير نشطة في وقت الاختبار ، لذلك لن يتم زيادة عينات الإدخال إلا أثناء الملاءمة () ، وليس عند استدعاء التقييم () أو التنبؤ ().
إذا كنت تتدرب النموذج على GPU ، فهذا هو الخيار الأفضل.
- الخيار 2: تطبيقه على مجموعة البيانات ، وذلك للحصول على مجموعة بيانات تنتج دفعات من الصور المعززة augmented images ، مثل هذا:
augmented_train_ds = train_ds.map(
lambda x, y: (data_augmentation(x, training=True), y))باستخدام هذا الخيار ، ستحدث زيادة البيانات الخاصة بك على وحدة المعالجة المركزية ، بشكل غير متزامن ، وسيتم تخزينها مؤقتًا قبل الانتقال إلى النموذج.
إذا كنت تدرب النموذج على وحدة المعالجة المركزية ، فهذا هو الخيار الأفضل ، لأنه يجعل زيادة البيانات غير متزامن و غير محظور.
في حالتنا في هذا المقال ، سنختار الخيار الأول.
تحضير و تجهيز مجموعة البيانات للأداء
دعنا نتأكد من استخدام الجلب المخزن مسبقا buffered prefetching حتى نتمكن من إنتاج البيانات من القرص دون أن يصبح الإدخال / الإخراج محظورًا:
train_ds = train_ds.prefetch(buffer_size=32)
val_ds = val_ds.prefetch(buffer_size=32)
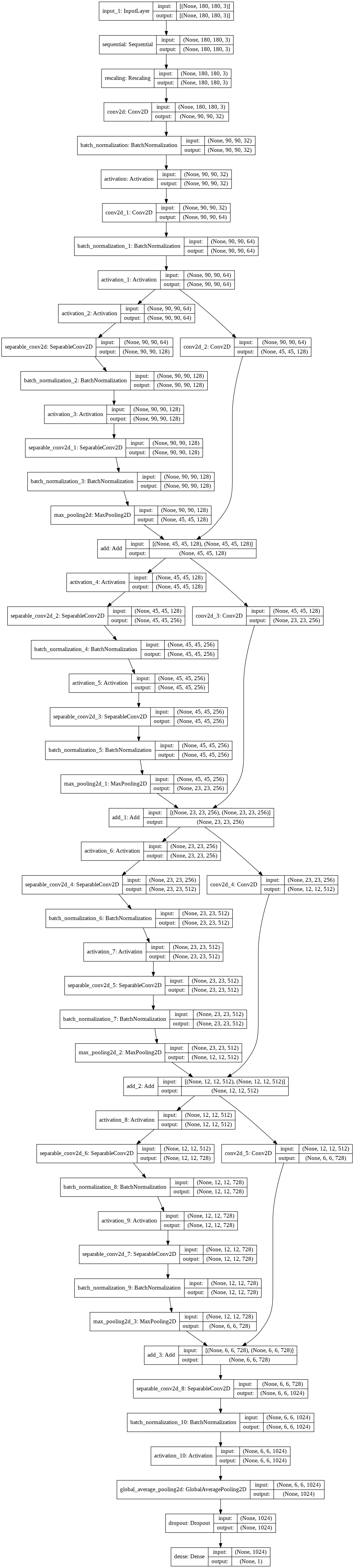
بناء نموذج
سنقوم ببناء نسخة صغيرة من شبكة Xception.
لاحظ أننا:
نبدأ النموذج بالمعالجة data_augmentation لزيادة البيانات ، متبوعًا بطبقة إعادة القياس Rescaling layer.
ثم نقوم بتضمين طبقة التسريب Dropout layerقبل طبقة التصنيف النهائية.
def make_model(input_shape, num_classes):
inputs = keras.Input(shape=input_shape)
# Image augmentation block
x = data_augmentation(inputs)
# Entry block
x = layers.Rescaling(1.0 / 255)(x)
x = layers.Conv2D(32, 3, strides=2, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.Conv2D(64, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
previous_block_activation = x # Set aside residual
for size in [128, 256, 512, 728]:
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
# Project residual
residual = layers.Conv2D(size, 1, strides=2, padding="same")(
previous_block_activation
)
x = layers.add([x, residual]) # Add back residual
previous_block_activation = x # Set aside next residual
x = layers.SeparableConv2D(1024, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.GlobalAveragePooling2D()(x)
if num_classes == 2:
activation = "sigmoid"
units = 1
else:
activation = "softmax"
units = num_classes
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(units, activation=activation)(x)
return keras.Model(inputs, outputs)
model = make_model(input_shape=image_size + (3,), num_classes=2)
keras.utils.plot_model(model, show_shapes=True)
تدريب النموذج
epochs = 50
callbacks = [
keras.callbacks.ModelCheckpoint("save_at_{epoch}.h5"),
]
model.compile(
optimizer=keras.optimizers.Adam(1e-3),
loss="binary_crossentropy",
metrics=["accuracy"],
)
model.fit(
train_ds, epochs=epochs, callbacks=callbacks, validation_data=val_ds,
)
النتائج ستكون مشابهه لأدناه
Epoch 1/50
586/586 [==============================] - 81s 139ms/step - loss: 0.6233 - accuracy: 0.6700 - val_loss: 0.7698 - val_accuracy: 0.6117
Epoch 2/50
586/586 [==============================] - 80s 137ms/step - loss: 0.4638 - accuracy: 0.7840 - val_loss: 0.4056 - val_accuracy: 0.8178
Epoch 3/50
586/586 [==============================] - 80s 137ms/step - loss: 0.3652 - accuracy: 0.8405 - val_loss: 0.3535 - val_accuracy: 0.8528
Epoch 4/50
586/586 [==============================] - 80s 137ms/step - loss: 0.3112 - accuracy: 0.8675 - val_loss: 0.2673 - val_accuracy: 0.8894
Epoch 5/50
586/586 [==============================] - 80s 137ms/step - loss: 0.2585 - accuracy: 0.8928 - val_loss: 0.6213 - val_accuracy: 0.7294
Epoch 6/50
586/586 [==============================] - 81s 138ms/step - loss: 0.2218 - accuracy: 0.9071 - val_loss: 0.2377 - val_accuracy: 0.8930
Epoch 7/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1992 - accuracy: 0.9169 - val_loss: 1.1273 - val_accuracy: 0.6254
Epoch 8/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1820 - accuracy: 0.9243 - val_loss: 0.1955 - val_accuracy: 0.9173
Epoch 9/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1694 - accuracy: 0.9308 - val_loss: 0.1602 - val_accuracy: 0.9314
Epoch 10/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1623 - accuracy: 0.9333 - val_loss: 0.1777 - val_accuracy: 0.9248
Epoch 11/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1522 - accuracy: 0.9365 - val_loss: 0.1562 - val_accuracy: 0.9400
Epoch 12/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1458 - accuracy: 0.9417 - val_loss: 0.1529 - val_accuracy: 0.9338
Epoch 13/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1368 - accuracy: 0.9433 - val_loss: 0.1694 - val_accuracy: 0.9259
Epoch 14/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1301 - accuracy: 0.9461 - val_loss: 0.1250 - val_accuracy: 0.9530
Epoch 15/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1261 - accuracy: 0.9483 - val_loss: 0.1548 - val_accuracy: 0.9353
Epoch 16/50
586/586 [==============================] - 81s 137ms/step - loss: 0.1241 - accuracy: 0.9497 - val_loss: 0.1376 - val_accuracy: 0.9464
Epoch 17/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1193 - accuracy: 0.9535 - val_loss: 0.1093 - val_accuracy: 0.9575
Epoch 18/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1107 - accuracy: 0.9558 - val_loss: 0.1488 - val_accuracy: 0.9432
Epoch 19/50
586/586 [==============================] - 80s 137ms/step - loss: 0.1175 - accuracy: 0.9532 - val_loss: 0.1380 - val_accuracy: 0.9421
Epoch 20/50
586/586 [==============================] - 81s 138ms/step - loss: 0.1026 - accuracy: 0.9584 - val_loss: 0.1293 - val_accuracy: 0.9485
Epoch 21/50
586/586 [==============================] - 80s 137ms/step - loss: 0.0977 - accuracy: 0.9606 - val_loss: 0.1105 - val_accuracy: 0.9573
Epoch 22/50
586/586 [==============================] - 80s 137ms/step - loss: 0.0983 - accuracy: 0.9610 - val_loss: 0.1023 - val_accuracy: 0.9633
Epoch 23/50
586/586 [==============================] - 80s 137ms/step - loss: 0.0776 - accuracy: 0.9694 - val_loss: 0.1176 - val_accuracy: 0.9530
Epoch 38/50
586/586 [==============================] - 80s 136ms/step - loss: 0.0596 - accuracy: 0.9768 - val_loss: 0.0967 - val_accuracy: 0.9633
Epoch 44/50
586/586 [==============================] - 80s 136ms/step - loss: 0.0504 - accuracy: 0.9792 - val_loss: 0.0984 - val_accuracy: 0.9663
Epoch 50/50
586/586 [==============================] - 80s 137ms/step - loss: 0.0486 - accuracy: 0.9817 - val_loss: 0.1157 - val_accuracy: 0.9609
<tensorflow.python.keras.callbacks.History at 0x7f1694135320>
تشغيل النموذج على البيانات الجديدة
img = keras.preprocessing.image.load_img( "PetImages/Cat/6779.jpg", target_size=image_size ) img_array = keras.preprocessing.image.img_to_array(img) img_array = tf.expand_dims(img_array, 0) # Create batch axis predictions = model.predict(img_array) score = predictions[0] print( "This image is %.2f percent cat and %.2f percent dog." % (100 * (1 - score), 100 * score) )
النتائج ستكون مشابهه لأدناه
This image is 84.34 percent cat and 15.66 percent dog.يمكن تحميل الكود أو تشغيله على Google Colab من هنا