تعد خوارزمية الغابة العشوائية Random Forest خوارزمية شائعة للتعلم الآلي التي تُستخدم في مهام التصنيف والتنبؤ. الخوارزمية تجمع بين العديد من أشجار القرار لتحسين دقة و متانة النموذج. لذلك في هذا المقال ، سنركز على خوارزمية الغابة العشوئية لمهام التصنيف و نقدم شرح خطوة بخطوة لتطبيقها في بايثون. علاوة على ذلك هذا البوست تعقيب للمثال السابق عن استخدام خوارزمية الغابة العشوائية Random Forest لحل مهام التنبؤ.
ما هي خوارزمية الغابة العشوائية Random Forest؟
هي خوارزمية تعلم آلي خاضع للإشراف تنشىء مجموعة من أشجار القرار باستخدام تقنية تسمى التعبئة Bagging. حيث يرمز الى التعبئة Bagging بالتجميع التمهيدي bootstrap aggregating ، الذي يتضمن أخذ عينات عشوائية من بيانات التدريب مع الاستبدال لإنشاء مجموعات فرعية متعددة من البيانات. حيث تُستخدم كل مجموعة فرعية لتدريب شجرة قرار ، ويتم دمج التنبؤات من جميع الأشجار لعمل التنبؤ النهائي. من ناحية أخرى تعد الغابة العشوائية خوارزمية قوية تُستخدم على نطاق واسع في الصناعة والبحث نظرًا لقدرتها على التعامل مع البيانات ذو الأبعاد المتعددة و البيانات الكبيرة ذو القيم المفقودة. كما أنها تعمل بشكل جيد على مجموعات البيانات غير المتوازنة ويمكن استخدامها لمهام التصنيف الثنائية ومتعددة الفئات.
مثال 1
بالنسبة لتطبيق الخوارزمية على بايثون لمهام التصنيف، سنستخدم مجموعة بيانات Iris الشهيرة لشرح كيفية عمل الخوارزمية على مهام التصنيف في بايثون. تحتوي مجموعة بيانات Iris على 150 عينة من ثلاثة أنواع مختلفة من أزهار القزحية ، مع أربع ميزات (طول السيبال ، وعرض السيبال ، وطول البتلة ، وعرض البتلة) لكل عينة. المهمة ترتكز على تصنيف كل عينة إلى زهرة واحدة من الأنواع الثلاثة بناءً على الميزات تبعها.
الخطوة 1: استيراد المكتبات وتحميل البيانات اللازمة حيث سنستخدم مكتبة scikit-Learn لتحميل مجموعة بيانات Iris ونموذج Random Forest Classifier لتشغيل مصنف الغابة العشوائية.
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score iris = load_iris() X = iris.data y = iris.target
الخطوة 2: تقسيم البيانات إلى مجموعات تدريب واختبار و ذلك باستخدام الدالة ()train_test_split من scikit-learn. تقوم هذه الدالة بتقسيم البيانات بشكل عشوائي إلى مجموعات تدريب و اختبار بناءً على نسبة محددة. في هذا المثال ، سنستخدم تقسيم 70 (بيانات التدريب) على 30 (بيانات الاختبار).
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
الخطوة 3: إنشاء وتدريب نموذج الغابة العشوائية حيث يمكننا إنشاءه و تدريبه باستخدام الدالة RandomForestClassifier () من scikit-Learn. يمكننا تحديد عدد أشجار القرار (n_estimators) والمعلمات التشعبية الأخرى مثل max_depth و min_samples_leaf لضبط أداء النموذج.
rf_model = RandomForestClassifier(n_estimators=100, max_depth=5, min_samples_leaf=3) rf_model.fit(X_train, y_train)
الخطوة 4: تقييم النموذج على بيانات الاختبار و ذلك باستخدام دالة () predict لعمل تنبؤات و دالة دقة ()accuracy_score من scikit-Learn لحساب دقة النموذج.
y_pred = rf_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
يجب أن يكون الناتج هو دقة نموذج الغابة العشوائية على بيانات الاختبار.
مثال 2
بالنسبة لإستخدام خوارزمية الغابة العشوائية لحل مسائل التصنيف (مثال 2) ، سوف نستخدم بيانات إعلانات شبكات التواصل الاجتماعي التي تحتوي على معلومات حول المنتج الذي تم شراؤه بناءً على عمر الشخص وراتبه.
أولا ، في البداية نستورد المكتبات الضرورية لتشغيل هذا النموذج.
import numpy as np import matplotlib.pyplot as plt import pandas as pd
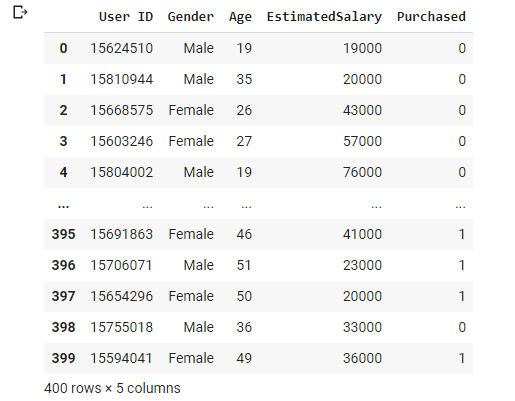
ثانيا ، نقوم بتحميل ملف البيانات الذي نزلناه من الموقع هنا و نقوم بإستعراض البيانات
df = pd.read_csv('Social_Network_Ads.csv')
df
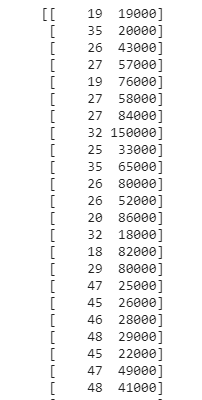
ثالثا ، من أجل تسهيل العمل نقوم بإزالة بعض الأعمدة غير الضرورية و نحدد أعمدة الميزات و عمود الهدف
X = df.iloc[:, [2, 3]].values y = df.iloc[:, 4].values print (X)
رابعا ، نقوم بتقسيم البيانات إلى بيانات تدريب لتدريب النموذج و بيانات إختبار لإختبار نتائج النموذج
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
خامسا، من مكتبة sklearn نقوم بإستدعاء الدالة StandardScaler من أجل ضبط البيانات
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
سادسا ، نقوم بملائمة النموذج بعد إستدعائة على البيانات التي حملناها
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0) model.fit(X_train, y_train)

بالنسبة لإعدادات النموذج لقد وضعنا 10 أشجار واستخدمنا المعيار “إنتروبيا entropy” حيث يتم استخدام هذه المعيار لتقليل القيم الشاذة في البيانات. يمكنك زيادة عدد الأشجار إذا كنت ترغب في ذلك ولكننا سنبقيها مقيدة بـ 10 في الوقت الحالي. الآن بعد إنتهائنا من إنشاء النموذج سوف نتوقع البيانات بإستخدام بيانات الاختبار.
y_prediction = model.predict(X_test)
سابعا ، بعد التنبؤ ، يمكننا إختبار النموذج من خلال مصفوفة الارباك Confusion matrix ومعرفة مدى جودة أداء النموذج.
from sklearn.metrics import confusion_matrix
conf_mat = confusion_matrix(y_test, y_prediction)
print(conf_mat)
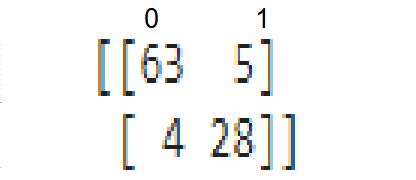
عظيم. كما نرى ، فإن نموذجنا يعمل بشكل جيد لأن معدل سوء التصنيف قليل وهو أمر مثير للاهتمام. الآن دعونا نرسم نتيجة تدريب نموذجنا.
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1,X2,model.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Random Forest Classification (Training set)')
plt.xlabel('Age')
plt.ylabel('Salary')
plt.legend()
plt.show()
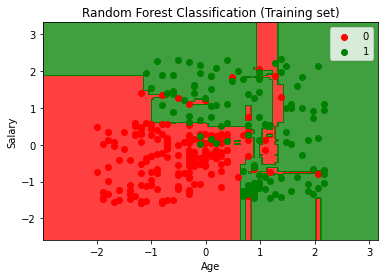
أخيرا ، هنا نتيجة إختبار النموذج.
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1,X2,model.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),alpha=0.75,cmap= ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Random Forest Classification (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
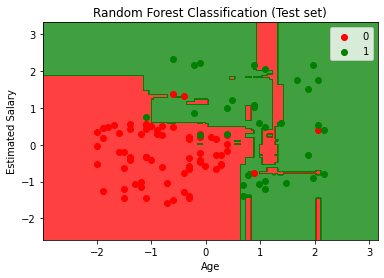
الخلاصة
في هذه المقالة ، قدمنا شرحا تفصيليًا لتطبيق خوارزمية الغابة العشوائية على مهام التصنيف في بايثون باستخدام مكتبة scikit-Learn. في الاخير، تعد خوارزمية Random Forest خوارزمية قوية تُستخدم على نطاق واسع في التعلم الآلي ويمكنها التعامل مع مجموعة متنوعة من مجموعات البيانات.