في هذا المقال سنقوم ب شرح خوارزمية SVM. حيث سنبدأ بتعريف الخوارزمية ، ثم شرح كيفية عملها ، و من ثم مثال عملي على تطبيق الخوارزمية على بايثون و أخيرا إيجابيات و سلبيات هذه الخوارزمية.
خوارزمية آلة المتجه الداعم SVM هي خوارزمية تعلم آلي خاضع للإشراف يمكن استخدامها في مسائل التصنيف Classification أو التنبؤ Regression. ومع ذلك ، فإنها تستخدم في الغالب في مسائل التصنيف. في خوارزمية SVM، نرسم كل عنصر من عناصر البيانات كنقطة في الفضاء ذو بعد n (حيث n هو عدد السمات Features) مع قيمة كل سمة هي قيمة إحداثيات معينة. ثم ، نقوم بإجراء التصنيف من خلال إيجاد المستو الفائق Hyper-plane الذي يميز الفئتين جيدًا. تتمثل الفكرة الرئيسية لـخوارزمية آلة المتجة الداعم SVM في العثور على حد القرار (المستوى الفائق) الذي يفصل إلى أقصى حد بين الفئات المختلفة في مساحة الميزة. يتم اختيار هذا المستوى الفائق ليكون المسوؤل عن زيادة المسافة بين أقرب نقاط كل فئة. هذه النقاط الأقرب تعرف بمتجهات الدعم ، وتعرف المسافة بينها بالهامش. انظر إلى الشكل أدناه لفهم ما تم الاشارة اليه.

المتجهات الداعمة Support Vectors هي ببساطة إحداثيات المراقبة الفردية. مصنف اله المتجهات الداعمة SVM Classifier هو الحد الفاصل بين الفئتين hyper-line / line.
كيفية عمل خوارزمية آلة المتجه الداعم SVM
أعلاه ، لاحظنا عملية الفصل بين الفئتين بمستوى فائق Hyper-plane. الآن السؤال المهم هنا هو كيف يمكننا تحديد المستوى الفائق الصحيح؟ ليس الأمر صعبًا كما تظن! يمكن شرحها ببساطة في الخطوات التالية:
سيناريو 1: حدد المستوى الفائق الصحيح
هنا ، لدينا ثلاثة مستويات فائقة (أ ، ب ، ج). الآن ، حدد المستوى الفائق الصحيح لتصنيف النجوم والداوئر.

تحتاج إلى تذكر قاعدة الإبهام لتحديد المستوى الفائق الصحيح: “حدد المستوى الفائق الذي يفصل بين الفئتين بشكل أفضل”. في هذا السيناريو ،يقوم المستوى الفائق “B” بتنفيذ هذه المهمة بشكل ممتاز.
سيناريو 2: حدد المستوى الفائق الصحيح
هنا ، لدينا ثلاثة مستويات فائقة (A و B و C) وجميعها تفصل الطبقات جيدًا. الآن ، كيف يمكننا تحديد المستوى الفائق الصحيح؟

هنا ، سيساعدنا زيادة المسافات بين أقرب نقطة بيانات (أي فئة) والمستوى الفائق على تحديد المستوى الفائق الصحيح. تسمى هذه المسافة بالهامش (Margin). دعنا نلقي نظرة على الصورة التالية:

أعلاه ، يمكنك أن ترى أن هامش المستوى الفائق C مرتفع مقارنة بكل من هوامش المستويين A و B. وبالتالي ، فإننا نختار المستوى الفائق الأيمن C كـافضل مستوى. سبب اخر لاختيار المستوى الفائق ذو الهامش الأعلى هو المتانة . إذا حددنا مستوى ذو هامش منخفض ، فهناك احتمالية لحدوث اخطاء اثناء عملية التصنيف.
سيناريو 3: حدد المستوى الفائق الصحيح
يتم إستخدم الخطوات التي تم مناقشتها في السيناريوهات السابقة لتحديد المستوى الفائق الصحيح.

قد تكون حددت المستوى الفائق B كافضل مستوى لأنه بهامش أعلى مقارنة بـالمستوى A. ولكن ، خوارزمية SVM هنا تختار المستوى الفائق الذي يصنف الفئات بدقة عالية بغض النظر عن زيادة الهامش. هنا ، يحتوي المستوى الفائق B على نسبة خطأ في التصنيف وقد عمل المستوى الفائق A التصنيف بشكل صحيح. لذلك ، فإن المستوى الفائق A هو الافضل.
سيناريو 4: هل يمكننك تصنيف الفئتين؟
في الشكل ادناه لا يمكننا الفصل بين الفئتين باستخدام خط مستقيم ، حيث تقع إحدى النجوم في مكان فئة الدائرة كشائبة.

كما ذكرنا سابقا ، فإن نجمة واحدة في الطرف الآخر يمثل عنصر غريب بالنسبة لفئة النجوم. تتميز خوارزمية SVM بميزة تجاهل القيم المتطرفة والعثور على المستوى الفائق الذي يحتوي على الحد الأقصى للهامش. وبالتالي ، يمكننا القول أن تصنيف SVM قوي إلى القيم المتطرفة.
سيناريو 5: ابحث عن المستوى الفائق للفصل بين الفئات
في السيناريو أدناه ، لا يمكن أن يكون لدينا مستوى فائق خطي بين الفئتين ، فكيف تصنف خوارزمية SVM هاتين الفئتين؟ حتى الآن ، نظرنا فقط إلى المستوى الفائق الخطي.

يمكن لـخوارزمية SVM حل هذه المشكلة بسهولة عن طريق إدخال ميزة إضافية. هنا ، سنضيف ميزة جديدة مستوى ثلاثي الابعاد 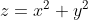 . الآن ، دعنا نرسم نقاط البيانات على المحور x و z:
. الآن ، دعنا نرسم نقاط البيانات على المحور x و z:

في المخطط أعلاه ، الاشياء التي يجب مراعاتها هي:
- ستكون جميع قيم z موجبة دائمًا لأن z هي مجموع مربع x و y.
- في المخطط الأصلي ، تظهر الدوائر الحمراء قريبة من أصل محوري x و y ، مما يؤدي إلى انخفاض قيمة z و النجوم بعيدًا نسبيًا عن نتيجة الأصل إلى قيمة z أعلى.
في مصنف SVM ، من السهل أن يكون لديك مستوى فائق خطي بين هاتين الفئتين. ولكن ، هناك سؤال ملح آخر يطرح نفسه ، هل يجب أن نضيف هذه الميزة يدويًا للحصول على مستوى فائق؟ الإجابة بالطبع لا. و ذلك لأن خوارزمية SVM لديها تقنية تسمى طريقة النواة Kernel method.
عند تطبيق هذه الطريقة على مثالنا ننظر إلى المستوى الفائق في مساحة الإدخال الأصلية ، حيث يبدو كدائرة كما هو موضح أدناه:

طريقة النواة Kernel method
في الممارسة العملية ، يمكن لـخوارزمية آلة المتجه الداعم SVM معالجة البيانات غير القابلة للفصل خطيًا عن طريق تعيين بيانات الإدخال إلى مساحة ذات أبعاد أعلى باستخدام طريقة النواة Kernel method. يسمح هذا لـخوارزمية آلة المتجه الداعم SVM بالعثور على المستوى الفائق الذي يمكنه فصل الفئات في مساحة الميزة الجديدة. طريقة النواة Kernal method هي عبارة عن اداة تعمل على تحويل المساحات ذي الأبعاد القليلة وتحوليها إلى مساحات ذي أبعاد متعددة (مثلا تحويل المستويات ذي البعدين الى مستويات ذي ثلاثة او اربعة أبعاد)، أي أنها تحول المسألة التي لا يمكن فصلها إلى مسألة قابلة للفصل. تفيد هذه الطريقة في الغالب في مسائل التصنيف غير الخطية. تتضمن بعض دوال النواة الشائعة دالة الأساس الخطية linear و متعددة الحدود polynomial و الشعاعية (RBF) والنواة السينية Sigmoid kernels.
مثال عملي لخوارزمية SVM في بايثون
في لغة البرمجة بايثون، يتم إستخدام مكتبة scikit-learn على نطاق واسع لتنفيذ خوارزميات التعلم الآلي. حيث يتم إستيراد خوارزمية SVM المتوفرة في المكتبة. من أجل فهم أعمق دعنا نلقي نظرة على المثال التالي لعملية التصنيف باستخدام SVM. سنقوم في هذا المثال بإستخدام خوارزمية SVM لتصنيف بيانات زهرة Iris.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
# Load the iris dataset
iris = datasets.load_iris()
# Use only the first two features for visualization
X = iris.data[:, :2]
y = iris.target
# Create a mesh grid to plot the decision boundary
h = 0.02 # step size in the mesh
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Define the SVM models with different kernels
models = (svm.SVC(kernel='linear', C=1.0),
svm.SVC(kernel='rbf', gamma=0.7, C=1.0),
svm.SVC(kernel='poly', degree=3, C=1.0),
svm.SVC(kernel='sigmoid', C=1.0))
# Create a new figure with a larger size
fig = plt.figure(figsize=(12, 8))
# Train each model and plot the decision boundary
for i, model in enumerate(models):
model.fit(X, y)
# Create a subplot for the current model
ax = fig.add_subplot(2, 2, i + 1)
# Plot the decision boundary
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)
ax.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
ax.set_title('Kernel: {}'.format(model.kernel))
# Display the plot
plt.show()
ضبط معلمات SVM الضرورية في بايثون
يؤدي ضبط قيم المعلمات لخوارزميات التعلم الآلي إلى تحسين أداء النموذج بشكل فعال. دعونا نلقي نظرة على قائمة المعلمات المتاحة مع SVM. بعض المعلمات المهمة التي لها تأثير أكبر على أداء النموذج ، “kernel” ، “gamma” و “C”:
النتائج مع kernels مختلفة

النتائج مع قيم جاما مختلفة
جاما تعرف بانها معامل النواة kernal لـ “rbf” و “poly” و “sigmoid”. كلما زادت قيمة جاما ، كلما زادت قيمة الخطأ و حدوث مشكلة الإفراط في التخصيص Overfitting. مثال: دعنا نرى تأثير قيم جاما المختلفة 0 – 10 – 100 على النتائج.
svc = svm.SVC(kernel='rbf', C=1,gamma=0).fit(X, y)

النتائج مع قيم مختلفة ل C

معامل الجزاء C لنسبة الخطأ. هذا المعامل يتحكم في المفاضلة بين حدود التصنيف الناعمة السلسة وتصنيف نقاط التدريب بشكل صحيح.
يجب أن ننظر دائمًا إلى النتائج للحصول على القيم المثالية للعوامل وتجنب الإفراط في التخصيص.
الإيجابيات والسلبيات المرتبطة بـخوارزمية SVM
الإيجابيات:
- تعمل بشكل جيد مع هامش فصل واضح.
- فعالة في المساحات ذات الأبعاد العالية.
- فعالة في الحالات التي يكون فيها عدد الأبعاد أكبر من عدد العينات.
- إمكانية إستخدم مجموعة فرعية من نقاط التدريب في دالة اتخاذ القرار (تسمى متجهات الدعم) ، لذا فهي أيضًا فعالة في الذاكرة.
السلبيات:
- لا تعمل بشكل جيد عندما يكون لدينا مجموعة بيانات كبيرة لأنها تتطلب وقت كثير للتدريب
- أداء هذه الخورازمية يكون سيء عندما تكون مجموعة البيانات تحتوي على قيم متطرفة كثيرة ، أي أن الفئات المستهدفة متداخلة
- لا تقدم خوارزمية SVM تقديرات الاحتمالات بشكل مباشر ، بل يتم حسابها باستخدام خوارزمية التحقق المتقاطع cross-validation باهظة التكلفة. حيث يتم تضمينه في طريقة SVC ذات الصلة في مكتبة Python Scikit-Learn.
تتمتع خوارزمية آلة المتجه الداعم SVM بالعديد من المزايا مقارنة بخوارزميات التصنيف الأخرى ، مثل قدرتها على التعامل مع البيانات عالية الأبعاد وقوتها ضد الإفراط في التخصيص. ومع ذلك ، يمكن أن تكون خوارزمية آلة المتجه الداعم SVM حساسة جدا لاختيار المعلمات الفائقة ويمكن أن تكون العملية مكلفة من الناحية الحسابية لمجموعات البيانات الكبيرة. لدى خوارزمية آلة المتجه الداعم SVM تطبيقات مختلفة مثل تصنيف الصور وتصنيف النص والمعلوماتية الحيوية.