الشبكة العصبية ذو المستقبلات متعددة الطبقات (شبكة MLP) هي نوع من الشبكات العصبية التي تستخدم على نطاق واسع في التعلم الآلي و الذكاء الاصطناعي. إنها شبكة عصبية متجهة إلى الأمام ، مما يعني أن المعلومات تتدفق في اتجاه واحد من طبقة الإدخال إلى طبقة الإخراج. تتكون بنية ال MLP من ثلاث طبقات أو أكثر: طبقة الإدخال Input layer، طبقة مخفية واحدة أو أكثر Hidden layer، و طبقة الإخراج Output layer. نقوم بتغذية طبقة الإدخال ببيانات الإدخال الخاصة بنا ونحصل على النتائج من طبقة الإخراج. يمكننا زيادة عدد الطبقة المخفية بقدر ما نشاء، لجعل النموذج أكثر دقة و تعقيدا وفقًا للمهمة التي نريد إنجازها.
بنية شبكة MLP
المخرج طبقة المخرج الطبقة المخفية 2 الطبقة المخفية 1 طبقة المدخل المدخل
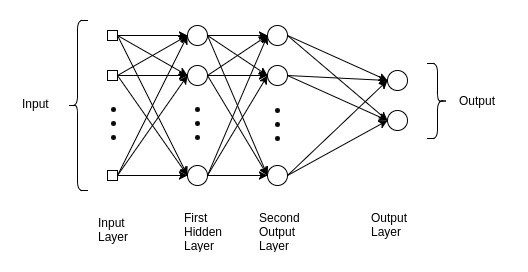
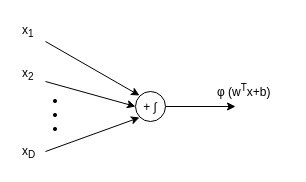
تتكون كل طبقة من مجموعة من العقد أو العصبونات المتصلة بالعقد الموجودة في الطبقات المجاورة. يتم ترجيح الروابط بين العقد في شبكة MLP ، ويتم تعليم هذه الأوزان أثناء عملية التدريب. الهدف من تدريب شبكة MLP هو ضبط الأوزان بطريقة تمكن النموذج من التنبؤ بدقة ببيانات الإخراج لمدخل معين. إذا كنت على دراية بخوارزمية المستقلات Perceptron Algorithm، فإننا في المستقبلات فقط نضرب الأوزان Weights في المدخلات Inputs و تضيف الانحياز Bias، لكننا نقوم بذلك فقط في طبقة واحدة. حيث تقوم الشبكة بتحديث الاوزان عندما تجد خطأ في التصنيف. معادلة تحديث الوزن هي كالتالي
الوزن weight = الوزن السابق weight + معدل التعلم learning_rate*(القيمة المتوقعه expected – القيمة التي تم ايجادها predicted) * قيمة المدخل x
دوال التنشيط و دالة الفقد في شبكة MLP
تستخدم الخلايا العصبية في الطبقات المخفية دالة تنشيط لتحويل المجموع المرجح للمدخلات إلى إشارة خرج. دالة التنشيط تعرف أيضًا بانها دالة غير خطية، وتصف العلاقات بين المدخلات والمخرجات بطريقة غير خطية. وهذا يعطي القوة النموذجية لتكون أكثر مرونة في وصف العلاقات المعقدة. فيما يلي دوال التنشيط الأكثر شيوعًا: الدالة السينية ، دالة الظل الزائدي (tanh) ، دالة الوحدة الخطية المصححة (ReLU). و يعتمد اختيار دالة التنشيط على المشكلة المطروحة ونوع البيانات التي تتم معالجتها.
أثناء عملية التدريب ، يتم تدريب شبكة ال MLP عادةً باستخدام خوارزمية تعلم خاضعة للإشراف ، مثل خوارزمية backpropagation. حيث تعمل الخوارزمية من خلال مقارنة ناتج شبكة ال MLP بالمخرجات المرغوبة و ضبط الأوزان بطريقة تقلل الخطأ بين المخرجات والمخرجات المرغوبة. تتكرر عملية التدريب عدة مرات حتى تنتج MLP الإخراج المطلوب لمدخل معين.
في التصنيف الخاضع للإشراف ، يرتبط كل متجه من متجهات المدخل بخاصية أو ميزة و يتم تحديد تعريف صنفه أو ترميزه مع البيانات. يعطي ناتج الشبكة درجة أو توقع لكل صنف. لقياس أداء المصنف classifier، يتم ايجاد دالة الفقد loss function. سيكون الفقد عالي إذا لم تتوافق القيمة المتوقعة مع القيمة الحقيقية ، فستكون منخفضة بخلاف ذلك.
في بعض الأحيان تحدث مشكلة الإفراط في التخصيص في وقت تدريب النموذج. في هذه الحالة، يعمل النموذج بشكل جيد جدًا على مجموعة بيانات التدريب و لكن ليس على مجموعة بيانات الاختبار. من أجل تدريب الشبكة، يلزم إجراء تحسين لذلك نحتاج إلى دالة الفقد loss function و المنظم optimizer. هذا الإجراء يجد قيم مجموعة الأوزان W التي تقلل من دالة الفقد.
الإستراتيجية الشائعة التي يتم تطبيقها هي تهيئة الأوزان للقيم العشوائية وتحسينها بشكل متكرر للحصول على فقد أقل. يتم تحقيق هذا التحسين من خلال التحرك في الاتجاه المحدد بواسطة ميل دالة الفقد loss function gradient. ومن المهم معرفة معدل التعلم الذي يحدد عدد الخطوات الذي تتحرك فيه الخوارزمية في كل تكرار.
تدريب نموذج MLP
هناك ثلاث خطوات أساسية يجب اتباعها عن تدريب النموذج.
1- التمرير الأمامي
في هذه الخطوة من تدريب النموذج ، نقوم بتمرير المدخلات إلى النموذج وضربهن بالأوزان و إضافة قيمة التحيز في كل طبقة و الحصول على المخرجات التي تم حسابها للنموذج.
2- حساب قيمة دالة الفقد
بمقارنة المخرجات التي تم تخمينها مع البيانات المتوقع الحصول عليها، نحسب الفقد أو نسبة الخطأ التي يتعين علينا إعادة نشرها (باستخدام خوارزمية الإنتشار العكسي Backpropagation). هناك العديد من دوال الفقد التي يمكن إستخدامها بناءً على المخرجات المتطلبة حسابها.
3- الانتشار الخلفي Backpropagation
نقاط يجب التركيز عليها عند تدريب شبكة MLP
اللاخطية Nonlinearity
دالتا التنشيط الأكثر شيوعًا هما الدالة السينية و دالة الظل الزائدي . للأسباب الموضحة سابقا ، يفضل إستخدام الدوال اللاخطية المتناظرة حول نقطة الصفر لأنها تميل إلى إخراج مدخلات متوسطة الصفر zero-mean inputs للطبقة التالية (وهي خاصية مرغوبة بها). تجريبيا ، دالة الظل الزائدي لها خصائص تقارب أفضل.
تهيئة الوزن Weight initialization
عند التهيئة ، نريد أن تكون الأوزان صغيرة بما يكفي حول المنشأ بحيث تعمل دالة التنشيط في نظامها الخطي ، حيث ان قيم الميل الإشتقاقي تكون الاكبر. يوجد أيضا خصائص أخرى غير مرغوب بها، خاصة في الشبكات العميقة ، هي الحفاظ على تباين التنشيط وكذلك تباين التدرجات الإشتقاقية المنتشرة عكسيا من طبقة إلى أخرى. وهذا يسمح بتدفق المعلومات بشكل جيد لأعلى ولأسفل في الشبكة ويقلل التناقضات و الاختلافات بين الطبقات.
معدل التعلم Learning rate
الحل الأبسط و الامثل هو الحصول على معدل ثابت. القاعدة الأساسية: جرب عدة قيم متباعدة و قم بتضييق الفارق إلى النقطة التي تحصل عندها على أدنى نسبة خطأ. أحيانًا يكون تقليل معدل التعلم بمرور الوقت فكرة جيدة.
عدد الوحدات المخفية hidden units
هذالعامل الفائق hyper-parameter يعتمد بشكل كبير على مجموعة البيانات.أي كلما كان توزيع المدخلات أكثر تعقيدًا ، زادت السعة التي ستحتاجها الشبكة لوضع نموذج لها ، وبالتالي كلما زاد عدد الوحدات المخفية التي ستكون مطلوبة (لاحظ أن عدد الأوزان في طبقة ما يساوي 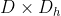 (D هو عدد المدخلات و D_h هو عدد الوحدات المخفية). ما لم نستخدم بعض أنظمة الضبط مثل (early stopping أو L1/L2 penalties) ، سيكون العدد المثالي للوحدات المخفية مقابل الرسم البياني لأداء التعميم على شكل حرف U.
(D هو عدد المدخلات و D_h هو عدد الوحدات المخفية). ما لم نستخدم بعض أنظمة الضبط مثل (early stopping أو L1/L2 penalties) ، سيكون العدد المثالي للوحدات المخفية مقابل الرسم البياني لأداء التعميم على شكل حرف U.