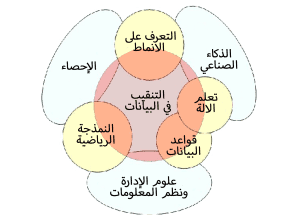
التنقيب في البيانات Data mining هي عملية إستخراج واكتشاف الأنماط في مجموعات البيانات الكبيرة التي تتضمن طرقًا عند تقاطع علوم التعلم الآلي و الإحصاءات وأنظمة قواعد البيانات. يعد علم التنقيب في البيانات مجالًا فرعيًا متعدد التخصصات لعلوم الكمبيوتر والإحصاء بهدف إستخراج المعلومات (باستخدام الأساليب الذكية) من مجموعة البيانات وتحويل المعلومات إلى بنية مفهومة للاستخدام الأمثل. التنقيب عن البيانات هو خطوة التحليل لعملية “اكتشاف المعرفة في قواعد البيانات” ، أو عملية اكتشاف المعرفة في قواعد البيانات الذي يختصر إسمها ب KDD. بصرف النظر عن خطوة التحليل الأولية ، فإنه يتضمن أيضًا جوانب إدارة قواعد البيانات ، والمعالجة المسبقة للبيانات ، واعتبارات النموذج و الاستدلال ، و مقاييس الاهتمام ، و اعتبارات التعقيد ، والمعالجة اللاحقة للهياكل المكتشفة ، والتصور ، والتحديث عبر الإنترنت.

مصطلح “التنقيب عن البيانات” تسمية خاطئة ، لأن الهدف من هذا العلم هو فقط استخراج الأنماط والمعرفة من كميات كبيرة من البيانات ، وليس استخراج (تعدين) البيانات نفسها. إنها أيضًا كلمة طنانة ويتم تطبيقها بشكل متكرر على أي شكل من أشكال البيانات أو معالجة البيانات على نطاق واسع (الجمع و الاستخراج والتخزين والتحليل والإحصاءات) بالإضافة إلى أي تطبيق لنظام دعم قرارات الكمبيوتر ، بما في ذلك الذكاء الاصطناعي. على سبيل المثال ، التعلم الآلي ML وذكاء الأعمال BI.
الفرق بين تحليل البيانات واستخراج البيانات هو أن تحليل البيانات يستخدم لاختبار النماذج والفرضيات على مجموعة البيانات ، على سبيل المثال ، تحليل فعالية حملة تسويقية ، بغض النظر عن كمية البيانات ؛ في المقابل ، يستخدم التنقيب عن البيانات التعلم الآلي والنماذج الإحصائية للكشف عن الأنماط السرية أو الخفية في حجم كبير من البيانات.
تشير المصطلحات ذات الصلة ، تجريف البيانات ، وصيد البيانات ، وتطفل البيانات إلى استخدام طرق استخراج البيانات لأخذ عينات من مجموعة بيانات أكبر حجمًا (أو قد تكون) صغيرة جدًا بحيث لا يمكن إجراء استنتاجات إحصائية موثوقة حول صحة أي اكتشف الأنماط. ومع ذلك ، يمكن استخدام هذه الأساليب في إنشاء فرضيات جديدة لاختبارها مقابل مجموعات البيانات الأكبر.
طرق معالجة التنقيب في البيانات
هناك طرق مختلفة للتنقيب في البيانات سنستعرض في هذا المقال ثلاث عمليات شائعة مختلفة في هذا المجال.
- عملية اكتشاف المعرفة في قواعد البيانات (KDD) بشكل عام تمر هذة العملية بالمراحل التالية:
- إختيار البيانات Selection
- ما قبل معالجة البيانات Pre-processing
- تحويل البيانات Transformation
- التنقيب في البيانات Data mining
- التفسير / التقييم Interpretation/evaluation
- العملية القياسية للتنقيب في البيانات Cross-industry standard process for data mining (CRISP-DM) التي تحدد في ست مراحل :
- فهم الأعمال Business understanding
- فهم البيانات Data understanding
- تحضير البيانات Data preparation
- النمذجة Modeling
- التقييم Evaluation
- التعيين Deployment
- عملية أخرى مبسطة تتكون من ثلاث مراحل
- المعالجة المسبقة
- التنقيب في البيانات
- التحقق من النتائج.
تشير استطلاعات الرأي التي أجريت في 2002 و 2004 و 2007 و 2014 إلى أن منهجية CRISP-DM هي المنهجية الرائدة المستخدمة من قبل باحثي التنقيب في البيانات مقارنة بمنهجية (SEMMA (Sample, Explore, Modify, Model, and Assess.
المهام الرئيسية في مجال التنقيب في البيانات
مهمة التنقيب عن البيانات الفعلية هي التحليل التلقائي أو شبه التلقائي لكميات ضخمة من البيانات لاستخراج أنماط مثيرة للاهتمام لم تكن معروفة من قبل. يتضمن التنقيب في البيانات ستة مهام رئيسية شائعة
- اكتشاف الشذوذ في البيانات Anomaly detection. هي مهمة تحديد سجلات البيانات غير العادية ، التي قد تكون مثيرة للاهتمام أو أخطاء البيانات التي تتطلب مزيدًا من التحقيق.
- تعلم قواعد الارتباط (نمذجة التبعية Association rule learning). تبحث هذه المهمة عن العلاقات بين المتغيرات. على سبيل المثال ، قد يجمع السوبر ماركت بيانات عن عادات الشراء لدى العملاء. باستخدام تعلم قواعد الارتباط ، يمكن للسوبر ماركت تحديد المنتجات التي يتم شراؤها بشكل متكرر معًا واستخدام هذه المعلومات لأغراض التسويق. يشار إلى هذا أحيانًا باسم تحليل سلة السوق.
- التجميع أو العنقدة Clustering. هي مهمة اكتشاف المجموعات والهياكل في البيانات التي تكون “متشابهة” بطريقة أو بأخرى ، دون استخدام الهياكل المعروفة في البيانات.
- التصنيف Classification. هي مهمة تعميم البنية المعروفة لتطبيقها على البيانات الجديدة. على سبيل المثال ، قد يحاول برنامج البريد الإلكتروني تصنيف بريد إلكتروني على أنه “شرعي” أو “بريد عشوائي”.
- الانحدار Regression. مهمة الإنحدار تحاول العثور على دالة تقوم بنمذجة البيانات بأقل خطأ ، لتقدير العلاقات بين متغيرات مجموعة البيانات.
- التلخيص Summarization. توفير تمثيل أكثر إحكاما لمجموعة البيانات ، بما في ذلك التمثيل المرئي وإنشاء التقارير.
يتضمن هذا عادةً استخدام تقنيات قواعد البيانات مثل المؤشرات المكانية. يمكن بعد ذلك النظر إلى هذه الأنماط كنوع من ملخص لبيانات الإدخال ، ويمكن استخدامها في التعلم الآلي و التحليلات التنبؤية. على سبيل المثال ، قد تحدد خطوة استخراج البيانات مجموعات متعددة في البيانات ، والتي يمكن استخدامها بعد ذلك للحصول على نتائج تنبؤ أكثر دقة من خلال نظام دعم القرار. لا يعد جمع البيانات أو إعداد البيانات أو تفسير النتائج وإعداد التقارير جزءًا من خطوة استخراج البيانات ، ولكنها تنتمي إلى عملية KDD الشاملة كخطوات إضافية