مع اكتساب عملية صنع القرار التي تعتمد على البيانات مزيدًا من الشعبية ، أصبحت نماذج التعلم الآلي ذات أهمية متزايدة. و مع ذلك ، مع التعقيد المتزايد للنماذج ، غالبًا ما يكون من الصعب تقييم أدائها. بناء على ذلك ، يأتي دور مصفوفة الإرباك Confusion Matrix. لخذا السبب في هذا المقال ، سنلقي نظرة عامة على مصفوفة الإرباك ، حيث سنشرح مكوناتها المختلفة و نوضح لك كيفية إنشاء واحدة باستخدام بايثون.
ما هي مصفوفة الإرباك Confusion Matrix؟
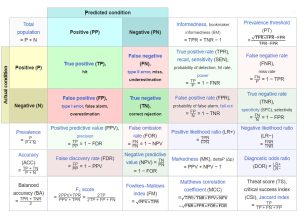
تعد مصفوفة الإرباك بانها جدول يُستخدم لتقييم أداء نموذج التصنيف حيث توضح عدد التنبؤات الصحيحة و غير الصحيحة التي قدمها النموذج مقارنة بالنتائج الفعلية. عادة ما يتم تمثيل المصفوفة في شكل جدولي بأربعة مكونات حيث يتم حساب هذه المكونات بناءً على توقعات النموذج والنتائج الفعلية:
- إيجابية صحيحة (TP): هذه القيمة تعبر عن عدد الحالات الإيجابية الفعلية التي توقعها النموذج بشكل صحيح على أنها إيجابية.
- سلبية صحيحة (TN): أما في ما يتعلق بهذه القيمة فهي تعبر عن عدد الحالات السلبية الفعلية التي توقعها النموذج بشكل صحيح على أنها سلبية.
- إيجابية خاطئة (FP): قيمة FP تعبر عن عدد الحالات السلبية الفعلية التي توقعها النموذج بشكل غير صحيح على أنها إيجابية.
- سلبية خاطئة (FN): تعبر عن عدد الحالات الإيجابية الفعلية التي توقعها النموذج بشكل غير صحيح على أنها سلبية.
لماذا تعتبر مصفوفة الإرباك مهمة؟
تعد هذة المصفوفة مهمة لأنها توفر فهمًا تفصيليًا و واضحًا لمدى جودة أداء نموذج التصنيف. علاوة على ذلك ، من خلال تحليل المصفوفة يمكننا تحديد نقاط القوة و الضعف في النموذج وإجراء التغييرات اللازمة لتحسين أدائه. زيادة على ذلك ، يمكن استخدام المصفوفة لحساب المقاييس المختلفة التي تساعد في تقييم أداء النموذج. على سبيل المثال ، بعض المقاييس الشائعة الاستخدام هي الدقة accuracy و الإنضباط precision و التذكر recall و مقياس F1 score.
مثال على تطبيق مصفوفة الإرباك Confusion Matrix في بايثون
يعد إنشاء مصفوفة الإرباك Confusion Matrix في بايثون أمرًا سهلاً. لذلك دعنا نفكر في مثال حيث يكون لدينا مشكلة تصنيف ثنائية. لنأخذ على سبيل المثال مهمة التنبؤ بما إذا كان الورم حميد أم لا. لذلك ، سنفترض أن لدينا مجموعة بيانات من 100 ورم، 80 منهم ورم حميد و 20 ورم خبيث.
أولاً ، نحتاج إلى استيراد المكتبات اللازمة:
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.metrics import confusion_matrix
بعد ذلك ، سننشئ مصفوفتين ، واحدة للنتائج الفعلية والأخرى لتنبؤات النموذج:
actual_outcomes = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]) model_predictions = np.array([0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
في الأخير ، يمكننا استخدام دالة confusion_matrix من مكتبة scikit-Learn لإنشاء المصفوفة:
conf_matrix = confusion_matrix(actual_outcomes, model_predictions) print(conf_matrix) Output: [[7 1] [0 12]]
كما توضح هذه المصفوفة أن النموذج تنبأ بشكل صحيح بأن سبعة اورام خبيثة (سلبية صحيحة) وأن 12 ورم ورم حميد (إيجابية صحيحة). و مع ذلك ، توقع النموذج بشكل غير صحيح أن ورم واحدًا (ورم خبيث) كورم حميد (إيجابي كاذب) و لا يوجد أي ورم حميد تم تم تصنيفة كورم خبيث (سلبي كاذب).
الخلاصة
في النهاية تعد مصفوفة الإرباك Confusion Matrix أداة حاسمة في تقييم أداء نماذج التصنيف. إضافة إلى ذلك توفر فهماً واضحاً لنقاط القوة والضعف في النموذج و يساعد على تحديد مجالات.
*يمكن تحميل الكود من على حسابنا على Github أو تشغيله على Colab.